anon_puqy said in #3749 13mo ago:
https://x.com/METR_Evals/status/1943360399220388093
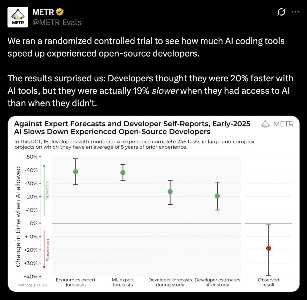
They tried to measure how much LLM assistance actually speeds up technical work but it came out negative! Programmers thought they would get +20%, they actually got -20%. What do you guys make of this?
The setup seems to be that they used professional programmers working on existing issues on github repos, and randomly assigned either having access to LLM tools or not. If there's nothing I'm missing, that's a pretty good methodology.
But this doesn't fit with all the vibe coding hype (which actually seems to be dying down if I'm not mistaken). Vibe coders claim huge speedups and new capabilities, but jonathan blow keeps challenging them to show impressive software coded by LLM assistance and say how long it took, and afaik, no one has taken him up on that. Meanwhile YC and big companies are apparently all in on vibe coding. What's going on?
I've met some people who apparently use LLM assistance effectively and swear it massively speeds up their ability to create complex apps. But others, while claiming similar things, seem to be engaged in a sort of ecstatic gnosis of the sort you see with psychedelic apologists. Does LLM use similarly dull your ability to see the reality of what you're actually doing?
In my own experience, LLM tools are great for looking up algorithms and thinking things through using it as a rubber duck who knows the literature and can do some math drudge work. But they noticeably have no ability to make tasteful tradeoffs, and just think everything is brilliant. So often what seems like a good idea while talking to an LLM turns out to be a bad idea on less technologized reflection. For coding, it's nice to have them spit out some boilerplate SQL interface code of the sort that shouldn't exist in the first place, but that's always twice as big as it should be, and often filled with subtle bugs. As soon as you get into subtle algorithms or making particular changes to complex systems, they are basically useless. They make too many assumptions and run off to do more stuff than can be understood, much of which breaks existing system assumptions or doesn't work. When you give them sufficiently detailed instructions that they don't trip up, you might as well write it yourself at that point. I've stopped using the coding agent type stuff because it was just too frustrating and it tended to be easier to just do it myself. I still use autocomplete, which seems like a boost, but this study has me questioning.
What's your experience, and do you think this study is sound? How well does the result generalize?
They tried to measure how much LLM assistance actually speeds up technical work but it came out negative! Programmers thought they would get +20%, they actually got -20%. What do you guys make of this?
The setup seems to be that they used professional programmers working on existing issues on github repos, and randomly assigned either having access to LLM tools or not. If there's nothing I'm missing, that's a pretty good methodology.
But this doesn't fit with all the vibe coding hype (which actually seems to be dying down if I'm not mistaken). Vibe coders claim huge speedups and new capabilities, but jonathan blow keeps challenging them to show impressive software coded by LLM assistance and say how long it took, and afaik, no one has taken him up on that. Meanwhile YC and big companies are apparently all in on vibe coding. What's going on?
I've met some people who apparently use LLM assistance effectively and swear it massively speeds up their ability to create complex apps. But others, while claiming similar things, seem to be engaged in a sort of ecstatic gnosis of the sort you see with psychedelic apologists. Does LLM use similarly dull your ability to see the reality of what you're actually doing?
In my own experience, LLM tools are great for looking up algorithms and thinking things through using it as a rubber duck who knows the literature and can do some math drudge work. But they noticeably have no ability to make tasteful tradeoffs, and just think everything is brilliant. So often what seems like a good idea while talking to an LLM turns out to be a bad idea on less technologized reflection. For coding, it's nice to have them spit out some boilerplate SQL interface code of the sort that shouldn't exist in the first place, but that's always twice as big as it should be, and often filled with subtle bugs. As soon as you get into subtle algorithms or making particular changes to complex systems, they are basically useless. They make too many assumptions and run off to do more stuff than can be understood, much of which breaks existing system assumptions or doesn't work. When you give them sufficiently detailed instructions that they don't trip up, you might as well write it yourself at that point. I've stopped using the coding agent type stuff because it was just too frustrating and it tended to be easier to just do it myself. I still use autocomplete, which seems like a boost, but this study has me questioning.
What's your experience, and do you think this study is sound? How well does the result generalize?
They tried to measur
