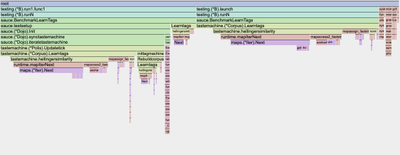
admin said in #3250 14mo ago:

Let's talk about the upcoming auto-tagger architecture. All it has to do is produce affinity scores between threads and tags, and our now existent smart tag selector will select a high-affinity set of tags that also make a good index. To do this, it's going to consider word frequencies. Word frequencies that match the distribution seen in a particular tag get a high affinity score with that tag.
The hypothesis is that at least some word frequencies are significantly correlated with tags. If any words like "lesswrong" "sofiechan" "god" etc are correlated with any tags like "rationality" "meta" or "theology", then we should be able to automatically measure that and use it to add information to the tag system unless we are utterly incompetent at statistics.
I tried various things and was defeated and humbled. However I persevered and now have a working similarity metric that is pretty fast and correctly guesses the thread of held-out test-set posts 60% of the time, and the author 20% of the time. That author result is crap considering how much I post here, but the thread result is much better, and more relevant to tagging. I think it's going to work!
The metric I've settled on is a fairly standard cosine similarity over TF-IDF frequencies (term frequency times negative log document frequency), with the slight modification that I do presence-conditional normalization of the term frequencies. "Term frequency" is how often the term in question appears in the post in question. "Document frequency" is what fraction of posts the term appears in. The "inverse document frequency" factor is the negative logarithm of document frequency, representing the information content (in nits) of the presence of that term. Presence-conditional normalization is when we normalize (divide) term frequencies by the frequency of that term in other documents that contain it, so that all terms have 1.0 frequency on average where they appear, and normalized term frequency measures relatively how much it appears. Presence conditional normalized tf-idf works slightly better than raw idf and is theoretically more correct IMO, while term frequency alone barely works because very common low-information words dominate the metrics.
Cosine similarity measures symmetrically how "close" two frequency distributions are by computing the cosine of the "angle" between them in their high-dimensional space. The nice thing about cosine similarity is that zeros make zero contribution so it can be super fast on sparse vectors (like our per-post term frequencies). We measure "similarity" between posts or threads and the bulk statistics of whatever category we are sorting them into. We're going to need something quite fast for the rapid iterations of measuring all threads against all tags that we're going to do.
The actual tag machine wants input in the form of thread-tag affinities that behave something like log likelihood ratios. We can get those by normalizing our cosine similarities into z scores for each tag or something like that. I haven't done this yet so it will take some experimentation. Log likelihood ratios of tags given the words in a thread are a perfect input for our tag selector. We combine them with information from user judgements, and feed it to the tag selector to pick a size-diverse non-redundant set of the highest affinity tags to be the actual tags of any given post.
We only need this to work well enough in practice to roughly but thoroughly imitate our tag preferences, but I think it will work better than that. If we iterate this process many times, the tag set will theoretically mutate on the margin to be both more predictive of post content and a better index from a structural perspective, while respecting our expressed preferences.
If this works, we're not too far off from having robot slaves to optimally organize our superintelligent discourse here on sofiechan dot com.
The hypothesis is that at least some word frequencies are significantly correlated with tags. If any words like "lesswrong" "sofiechan" "god" etc are correlated with any tags like "rationality" "meta" or "theology", then we should be able to automatically measure that and use it to add information to the tag system unless we are utterly incompetent at statistics.
I tried various things and was defeated and humbled. However I persevered and now have a working similarity metric that is pretty fast and correctly guesses the thread of held-out test-set posts 60% of the time, and the author 20% of the time. That author result is crap considering how much I post here, but the thread result is much better, and more relevant to tagging. I think it's going to work!
The metric I've settled on is a fairly standard cosine similarity over TF-IDF frequencies (term frequency times negative log document frequency), with the slight modification that I do presence-conditional normalization of the term frequencies. "Term frequency" is how often the term in question appears in the post in question. "Document frequency" is what fraction of posts the term appears in. The "inverse document frequency" factor is the negative logarithm of document frequency, representing the information content (in nits) of the presence of that term. Presence-conditional normalization is when we normalize (divide) term frequencies by the frequency of that term in other documents that contain it, so that all terms have 1.0 frequency on average where they appear, and normalized term frequency measures relatively how much it appears. Presence conditional normalized tf-idf works slightly better than raw idf and is theoretically more correct IMO, while term frequency alone barely works because very common low-information words dominate the metrics.
Cosine similarity measures symmetrically how "close" two frequency distributions are by computing the cosine of the "angle" between them in their high-dimensional space. The nice thing about cosine similarity is that zeros make zero contribution so it can be super fast on sparse vectors (like our per-post term frequencies). We measure "similarity" between posts or threads and the bulk statistics of whatever category we are sorting them into. We're going to need something quite fast for the rapid iterations of measuring all threads against all tags that we're going to do.
The actual tag machine wants input in the form of thread-tag affinities that behave something like log likelihood ratios. We can get those by normalizing our cosine similarities into z scores for each tag or something like that. I haven't done this yet so it will take some experimentation. Log likelihood ratios of tags given the words in a thread are a perfect input for our tag selector. We combine them with information from user judgements, and feed it to the tag selector to pick a size-diverse non-redundant set of the highest affinity tags to be the actual tags of any given post.
We only need this to work well enough in practice to roughly but thoroughly imitate our tag preferences, but I think it will work better than that. If we iterate this process many times, the tag set will theoretically mutate on the margin to be both more predictive of post content and a better index from a structural perspective, while respecting our expressed preferences.
If this works, we're not too far off from having robot slaves to optimally organize our superintelligent discourse here on sofiechan dot com.
referenced by: >>3268
Let's talk about the