A know what you're thinking: anon's gone all kooky mashing together a bunch of mysterious things, wrapping it in some gold foil, and worshipping it as an idol. Maybe, maybe not. Hear me out.
I attended Charles Rosenbauer's talk on NP at Avalon the other day, and while Charles is a notoriously disorganized speaker, the subject matter was fascinating. To reiterate, NP is the class of problems whose solutions can be verified quickly (polynomial time) and thus could be solved by an imaginary Nondeterministic (N-) computer in Polynomial (-P) time by trying all possibilities in parallel (impossible in reality). More specifically, we are interested in the NP-complete problems, which can't be solved quickly in the general case by real deterministic computers as far as we know (P!=NP), and to which all other problems in NP can be reduced.
NP-complete somehow rhymes with Turing-complete. There is a universality class here: any algorithm that can solve one of these problems can solve all of them, and many others besides, just as any universal computer can emulate all of them. I have suspected something like a universality class underlying intelligence and life, so I am taking note of this.
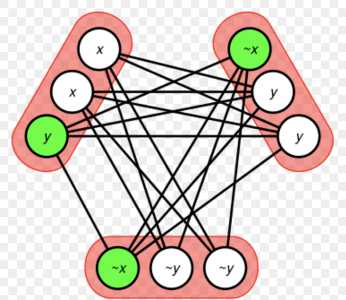
The most obvious and intuitive of these problems is the BSAT (Boolean SATisfiability) problem: given a set of binary variables and binary constraint expressions over those variables, is there a setting of those variables that satisfies all the constraints? A solution can be verified by simply checking the constraints, but they are not so easily found. You can build just about anything with arbitrary binary logic circuits, so the ability to solve such problems is extremely powerful. For example, you could invert most functions, including cryptography. However if P!=NP, then there's no general algorithm to solve these better than raw exponential brute force.
But in practice, practical problems that are best expressed in NP complete terms in fact can be solved quite rapidly. Cutting edge BSAT algorithms rip through them in much less than exponential time. The best of these are learning algorithms. They assume the problem has some repeatable structure, like a core of key variables that determine the rest, or repeatable connections between seemingly distant variable clusters, and they learn that structure inductively. For example, when they encounter a contradiction in one of their guesses, they trace the causal origin of that contradiction, invent a new constraint to capture that causality, and then backtrack and re-try other possibilities taking the now-explicit constraint into account. As inductive learners, they don't work on random problems, only problems constructed from actual reality.
This brings us to the connection to life and intelligence. Life is "verifiable in polynomial time" as the "solution" to a niche: just run the organism in the niche and see if it reproduces. Or if we're thinking about intelligence more broadly, you can verify skill in a domain by just seeing if it can take on the domain and produce results within some resource constraint. But how to produce such organisms and such skills? Bruteforcing the genetics of an organism or the weights of a domain model is not tractable. And in the general case that's probably what you have to do. Life is NP-complete.
But we don't live in the general case. We live in reality, which is not cryptographically secure against life, but has exploitable regularities all over the place. All you need is an inductive process to learn those regularities: Darwin tells us organisms come from an inductive process of natural selection over hereditary mutations. Hinton tells us at least domain-specific intelligence can be created by an inductive process (gradient descent with backprop). Both processes work by learning the repeatable structure of the problem.
There's something very interesting here. Could you construct BSAT-based AI, or solve BSAT problems with gradient descent?
There is indeed something interesting here about life and intelligence, but I don't think it has much to do with NP or BSAT.
It's more in the vicinity of why it is that the No Free Lunch theorems do not, in practice, block induction or machine learning algorithms. A naive interpretation of the No Free Lunch theorems says that induction and learning should be impossible. But that's from a perspective ranging over all possible worlds, i.e., no informative prior. In reality, in our world, we know that induction and learning do work. And so do life and intelligence.
>>3500 Well we know why no free lunch theorems don't block practical compression and induction: because reality is in fact quite structured and thus describable with simple inductive priors.
As for BSAT, no life is not about BSAT in particular, but the nice thing about NP complete problems is they are all equivalent up to a polynomial time translation. I gave my argument above that there's something NP-complete-ish about the problem life and intelligence are solving. I don't think it's literally NP-complete because I don't think the problem is that formal and self-contained, but I think it's the same type of difficulty, with the same type of solution (induction).
But you are right there's something additional in the problem of life that takes it beyond mere NP-complete and possibly beyond mere induction. We have good inductive models of eg the world's text, but they aren't intelligent or alive per se. That extra thing is dynamism. Life solves a dynamic problem, where the "training data" or "constraints" are discovered as a direct result of the system's output, rather than the system just being statically fit to a fixed set of training constraints. What's that about?
But I'm also still curious about whether there's a formal connection between what's going on with NP complete problems and what's going on with deep learning. I suspect we will get an answer one of these days when victor taelin or someone trains a language model using his GPU accelerated interaction nets or something instead of deep learning. Basically, are NP complete problems also program synthesis problems, and are program synthesis problems NP complete (yes, I think).
Then the remainder is just that dynamism problem. What's the difference between a dynamic program syntheses problem and a static one?
NP problems including NP complete ones can be verified in polynomial time. But it seems life generates solutions that can't be verified tractably sometimes. Many zero sum games like N x N Reversi are PSPACE-complete. See True Quantified Boolean Problems https://en.wikipedia.org/wiki/True_quantified_Boolean_formula
To square with the idea of verifying an organism by placing it in an environment, consider that this only tells how well it does in a fixed environment, with fixed competitors. This doesn't tell you how "meta" the strategy is because it's relative to a fixed set of competitors. Doing well at a zero sum game in general isn't just doing well against a finite set of competitors, it's doing well against a set of possible competitors that are themselves optimized for playing well.
>>3503 Well life is at least a solution to what has been, verified in reasonable time. Where it starts to break the model as you point out is where it starts to become dynamic and reflexive. The metagame is a whole new level of dynamism as well beyond what I was talking about. But still at the root there's this NP-like asymmetry. Try every lifeform that could exist and see which ones work. Is that a description of what darwin's process is approximating, or a nondeterministic solution to the problem of life? Well it's both.
>>3496 An off-topic comment but important to bring up: I saw the best minds of my generation get nerdsniped for years by category theory. Complexity theory, especially after attending Charles’ talk, seems to me to be another one of these ‘highly ontological unification schemes’. So while I like the interrogative nature of your OP, there is in fact something about this particular variety of thinking that tends to produce clouds of farts.
That said, if your infinite tower partitioning of a problem space reliably enables theorems and proof techniques native to field X to be used in field Y, well that’s no cloud of farts anymore. But I have seen what unifying fields in a truly practical or divinely inspired way looks like, and it frankly does not resemble what I have seen from the complexity crowd.
>>3507 This is a very fair caution. Nerd towers of abstraction are a great way to waste one’s time. In this case, the focus is less on complexity theory and more on this interesting thing which is the surprising tractability in practice of theoretically hard problems, and the way this relates to life and intelligence. I suppose the equivalence class established by the idea of np complete is a classic of the “theorems from here can be applied there” genre, if we can fit things into the class well enough. My main takeaway from all this is i have to figure out more precisely what i mean by “dynamism” and that i should investigate the formal relationship between different inductive strategies for hard problems (gradient descent, genetic algos, CDCL, etc).
>>3512 > ... the surprising tractability in practice of theoretically hard problems ...
But it's not surprising, and it misunderstands the definitions to think it is.
Assuming P/=NP, then all NP-complete problems have worst-case exponential complexity. The key words there are "worst-case." This does not at all preclude algorithms that are polynomial for most practical cases (like CDCL for SAT), or very fast approximation algorithms (which is what industry uses for the Traveling Salesman problems). This is just a straightforward consequence of "worst-case" vs. "average-case" vs. "approximation."
All of this has been understood for a long time (CDCL was introduced in 1996), even though Charles didn't address it in his talk.
There's definitely a lot of stuff that had to get ~left out~ of the talk for the sake of time. I think I got through about a third of the notes I had, and there's plenty more I could have talked about that wasn't in the notes.
Overall, I don't think there's any reason to believe that all of the meaningful problems in the world will land in a nice subset of complexity classes, we should expect meaningful problems to be arise at every level of complexity. We mostly stick to P in our engineering, but there are a lot of things going on in NP that add a lot of interesting new factors, and things that are frequently echoed in complexity classes beyond. Something briefly mentioned at the end of the talk (and mentioned by another user here) is the Polynomial Hierarchy and QBF, which is essentially an infinite tower of generalizations of NP, and is PSPACE-complete.
In the context of games, the intuition for QBF is perhaps that deciding a move that doesn't cause a loss on a given turn may be NP, but then finding one that doesn't allow the enemy to defeat you in the next turn, and deciding your move the turn after, and so on, requires a form of nested nondeterminism.
Ultimately the interesting thing here is this notion of nondeterminism, NP is really just the easiest example to study, and the one closest to a lot of the kinds of problems we're familiar with.
The biochemistry/life argument at the end of the talk is largely that reaching chemical equilibrium in a cell is NP-complete, and has a lot of nice advantages in terms of being able to solve nondeterministic problems quickly, as well as encoding them in a way that may make them easier to evolve. That doesn't mean that all problems life solves must be in NP - DNA is more or less Turing-complete. A perhaps more nuanced argument is that biology has a natural "nondeterminism accelerator" that buys it a lot of advantages.
Program synthesis requires a lot of nondeterminism. You can argue that it's Turing-complete, though in practice it doesn't take too many reasonable constraints to define something in a low level of PH that's pretty close. The only reason why mathematical theorem proving is Turing-complete rather than NP-complete is that proofs can be unbounded - if you limit yourself to proofs of a finite size, this approximation of mathematics is in NP. There is of course the Curry-Howard correspondence then.
With regards to how well these problems can be solved in practice, there's some nuance here that should be highlighted. "BSAT solvers can solve all real-world problems" is definitely not true. They are surprisingly useful in practice, but they still scale exponentially as you make problems bigger. Exponential problems can alternatively be viewed as "easy until you hit a wall". Where that wall is depends on how long you're willing to wait, but if you simply shrink the problem below that threshold, they also get exponentially easier. There's an annual "SAT solver competition" and they have large numbers of benchmark files you can dig through, that are all meant to be similarly "hard". There are some with hundreds of millions of variables, others with only a few hundred, and everything in between. There really isn't any good line you can draw between what's "real world" and what's not.
You can find digital circuit problems with millions of variables that are tractable. You can also find pretty straightforward ones which are not (proving a*b=b*a with a BSAT solver is notoriously hard). There's no reason why you can't devise digital circuit problems that would be very useful that require billions or trillions of variables - modern CPUs often have tens or hundreds of billions of transistors! But things scale exponentially, and you do eventually hit a wall on what can be solved in a reasonable time.
Also, arguing about "polynomial" and "exponential" time here does get to be a bit imprecise when you're only talking about individual problems and not classes of problems of varying sizes. It's akin to asking "I have a function where f(x) = 4, what the derivative at x?". Who knows? You haven't defined the function beyond that point. Even if the function is exponential, the derivative can be anything, it's how all the higher-order derivatives correlate which decide if it's an exponential or polynomial function. Colloquially, "polynomial time" seems to be just be used in these discussions as a shorthand for "solved in a reasonable amount of time", and I think that causes a deal of confusion. Granted, it's something tricky to deal with in the math anyway, and I suspect that there are some deeper geometric principles in play. A 1.00001^N problem is still exponential. 2^N is much harder, but even a 2^40 problem can be brute forced by a modern GPU in a fraction of second, and many SoTA LLMs are trained with on the order of 2^80 FLOPS.
With regards to the deeper and obscure geometric principles, exponential functions can of course be interpreted as a sum of polynomials, like with a Taylor series. If the talk had gone on longer, this would have been addressed directly along with some ways of tying these Taylor series approximations directly to actual bounds on BSAT solver algorithms. A 500-bit BSAT problem is in some sense equivalent to some N^k polynomial problem where k<=500. Polynomial problems just have a finite upper bound for this polynomial degree - an N^2 problem doesn't get harder than N^2 as you make N bigger. An individual instance of an exponential problem can also be viewed as equivalent to some polynomial problem, but where the degree of the bounding polynomial grows with some function dependent on the input size.
The constraints in a BSAT problem will correlate the variables with each other. Some of these constraints are very local, tight, and deterministic, and you can get big information cascades that collapse arbitrary numbers of variables from a small number of guesses. That's what going on with unit propagation in DPLL/CDCL. If you have a cryptographic function like SHA256, the input space is 256 bits but you need many tens of thousands of bits to encode the rest of the circuit as BSAT. If you only make guesses on input bits (running it forward, which is in P), the inputs propagate deterministically through the rest of the circuit. A lot of what makes many NP problems easy in practice is that the transformation into BSAT leaves a lot of big, locally deterministic subcircuits. What makes things hard is that you can have longer, more complex correlations between relatively unconstrained variables, which can be very difficult to resolve. Which variables you collapse and how you collapse them also has a big impact - collapsing the inputs to derive the outputs on SHA256 is completely in P, collapsing the outputs to derive the inputs is much harder! Nevertheless, a SHA256 problem is in a sense a 256-bit problem disguised as a much bigger problem.
Perhaps a notion of "combinatorial density" may be intuitive here, as in "how far apart are variables that do not strongly correlate with each other, such that you can't efficiently infer one from another?" Though computing such a thing for a given problem in practice is hard, and the density may vary across different parts of the same problem. Many real-world problems have low average densities (high density seems to be related to chaos). Nevertheless, you do still eventually hit exponential scaling walls as you make the problems bigger, the actual difficulty is more approximately a product of density and scale rather than just scale.
(The size of these correlations is also related to the degree of the Taylor series expansions, as well as the amount of entanglement in the quantum mechanics analogy that was briefly mentioned in the talk).
Can you construct BSAT-based AI? I think BSAT is in some respects a slightly different problem from ML, in that ML is constructing a model from data and BSAT is trying to sample states in a given model. Nevertheless, there's related structure. I know finding optimal weights in a neural network for a given training set was proven a long time ago to be NP-Hard (anything harder than ordinary NP, probably just somewhere in PH). AlphaGO and some other AIs have combined ML with backtracking search algorithms, and I have some arguments about how the basal ganglia circuit in the brain is also implementing a variant of backtracking.
Can you solve BSAT problems with gradient descent - this was covered in detail in the talk, kind of. You can construct a function that operates over BSAT problems that closely resembles discrete gradient descent.
There are exploitable regularities everywhere for life to take advantage of - yes! There's also a lot of chaos which is much harder to exploit, and lots of stuff in between. If every cell is a kind of chemical constraint solver as posited in the talk, and each chemical reaction a computation, that's a gigantic amount of compute when you consider how many organisms there are on Earth and how many billions of years it has taken to compute their current genomes. I think that aligns well with there still being a gigantic amount of cryptographic/chaotic structure, even if there's a lot of low-hanging fruit and gradients.
Overall, there are a lot of nice arguments people can make about gradient descent and similar algorithms, and how they can converge to decent solutions and often much faster than expected. However, precisely how long it takes to converge, and what factors accelerate or slow that convergence is something that's beyond the scope of most of this discussion, and this complexity theory discussion is meant to in part provide some tools for being able to talk about this and other things with a bit more precision. It's worth noting that all the "AI scaling laws" are still very much exponential, which is perfectly consistent with everything I'm saying. I think part of what's going on with LLMs is that language has relatively low combinatorial density and we have gigantic datasets of accumulated knowledge on almost any problem people can presently think of, and people are surprised from this in a similar way as to how people were with overbalanced wheels engineered to spin for a couple days.
Actually, another thing I'll quickly add related to life -
The cryptographic nature of nondeterminism also means that a relatively small amount of secret knowledge or specialization can outperform exponentially large amounts of general compute. If P=NP and by extension this were not the case, or even if P~=NP and there were some sufficiently general algorithms for quickly solving basically anything, you wouldn't expect to see such an enormous diversity of life specialized to different niches.
There are some notable caveats to this of course. A huge amount of the biodiversity of insects disappeared after the evolution of eusocial insects like ants, bees, wasps, and termites. Eusocial insects may have been a more general and more efficient configuration that ate up a lot of niches. Nevertheless, there is still no shortage of other insects that were not outcompeted.
Humans are pretty general purpose in a lot of ways too, but note that our economy is not one based on 8 billion jacks-of-all-trades, but rather a large degree of specialization of labor. Tool use is largely a matter of building nonhuman things to solve problems that humans on their own cannot solve. Agriculture involves a great deal of domestication, relying heavily on plants and animals to do things we are not general-purpose enough to do on our own, and industrialization is to some extent domestication of machines, or an extension of tool use (though I have many deeper thoughts on industrialization that are beyond the scope of this discussion).
There is perhaps an interpretation here, which is that the advantage of humans (and eusocial insects as well) is less in general-purpose problem solving, and more the ability to coordinate and align large groups of individually specialized beings/tools to fill many niches simultaneously. The internals of the brain can perhaps be viewed as aligning large volumes of accumulated knowledge for individual survival.
>>3550 > ... reaching chemical equilibrium in a cell is NP-complete, and has a lot of nice advantages in terms of being able to solve nondeterministic problems quickly ...
Why should we believe that the cell is in fact solving this problem, as opposed to a very good approximation of it, analogous to the way in which industry usually employs fast approximation algorithms for Traveling Salesman rather than solve the strict problem?
>>3557 Strictly speaking i suppose we should expect just one optimum and not necessarily a global one. On the other hand some NP complete problems are about solution existence and others are about solution optimality. I forget how one is translated into the other.
>>3552 On BSAT AI, if we think of data as constraints and the model as what we are trying to sample, i think BSAT AI is not totally incoherent.
As for gradient descent yes i remember your discrete “gradient descent” scheme but i was not convinced that it actually has anything to do with gradient descent. What i mean by solve BSAT with gradient descent is some scheme to represent the space of solutions continuously in high dimensions such that solutions are minima and there arent other minima. Then we can apply standard continuous gradient descent as the optimizer and let it eventually find a viable minimum, though it may be very difficult or impractical the theoretical connection would be interesting.
Overall many good technical objections to my ideas in OP in this thread, but the idea of really substantiating what connection there is if any between these nondeterministic problem spaces and intelligence and life is still unanswered, as is the question of what is the dynamism that separates the latter from the former. I will think more about them.
>>3571 But what if you did modern bitter lesson-pilled data driven AI with BSAT? Many AI systems reach *perfect* zero training error ie perfect overparameterized overfitting, and somehow still get good test error because for whatever reason the types of functions that result from training and get low loss generalize decently well. I think the simple answer is expressivity + regularization = generalization as one might predict from inductive priors. With plain BSAT this would not work (the first satisfying match would be overfit as hell) without some kind of regularization scheme, which definitely breaks the plain BSAT paradigm. But the other thing you would have to figure out is how to express arbitrary parameterized functions in the BSAT paradigm. A binary neural network would be fine probably. Would it be tractable with CDCL? Probably not but it would be interesting to know.
This may seem like a silly line of inquiry, but sometimes showing that something can be done in a different way results in a generalization. In particular the generalization here is to explore non-SGD training paradigms. Between SGD, program synthesis, regularized constraint solvers, and genetic algorithms I bet there's a general class and general theory of data driven learning and even superior algorithms.
Does anyone (charles?) happen to know what the "error" of BSAT solvers looks like as they approach the "right" solution? Are they walking the search space of assignments apparently randomly, or are they incrementally working out the problem and then focusing on the hard parts?
>>3573 > ... what if you did modern bitter lesson-pilled data driven AI with BSAT?
You're on to something, but I think B-SAT is the wrong problem to work with. If you want to apply modern deep learning to an NP-complete problem that can serve as general target for problem translations, you want a problem that has a natural metric on solutions, so that it makes sense to talk about "good but imperfect" solutions.
That's not B-SAT. In B-SAT, a single bit being wrong in a large problem can make the entire solution worthless.
If I were researching in this area, I would look for a general NP-hard problem with a metric. For example, MAX-SAT has a natural metric on solutions, the number of clauses satisfied. MAX-SAT also has good approximation algorithms, such as Avidor, Berkovitch, Zwick algorithm.